
はじめに
WebページからVaporアプリケーションを通じてMongoDBのドキュメントの一覧を表示するところまでできました。今度は、タイトルの部分一致検索ができるようにしてみます。
ページネーションできる状態で部分一致検索を追加してみる
フロントエンドから検索語句を渡す
フロントエンドから検索語句をVaporアプリケーションへ渡すために、クエリパラメータを使うことにしました。ページネーションのときにページ番号を渡せるようにしているので、そこに付け加えます。
/api/books?page=[ページ番号]&q=[検索語句]渡された検索語句でMongoDBのドキュメントを絞り込む
ドキュメントの部分一致検索での絞り込みは以前やってみましたので、それを応用してみます。

let booksDocs = try! collection.find().filter({ book -> Bool in
return book.title.contains(title)
})部分一致検索の絞り込みとページネーションの順序に注意
ここで注意することがあります。それは部分一致検索の絞り込みとページネーションの順序です。
ページネーションをするときは検索結果を制限するために、先頭からスキップするドキュメント数と、スキップしてから取得するドキュメント数を指定しました。
let booksDocs = try! collection
.find(
Document.init()
, options: FindOptions(limit: Int64(LIMIT)
, skip: Int64((pageNumber-1)*LIMIT))
, session: nil)先ほどの絞り込みのコードと見比べてみてほしいのですが、filterはfindの後に続けなくてはいけません。コレクションの中身からドキュメントを取り出してから絞り込みという順序です。取り出してもいないドキュメントを絞り込むことはできない理屈です。
指定したページに表示されているものを絞り込むとうまく行かない
ならば、と素直に、
let booksDocs = try! collection
.find(
Document.init()
, options: FindOptions(limit: Int64(LIMIT)
, skip: Int64((pageNumber-1)*LIMIT))
, session: nil)
.filter(
{ book -> Bool in
return book.title.contains(title)
})なんてことをしてはいけません。
これは指定したページに表示するべきドキュメントを取得した後、条件に合うもののみを絞り込むことを意味しています。ですので、場合によっては途中ページでドキュメントが表示されないという状況もあり得ることになります。
絞り込みはできているとはいえ、ページネーションの意味合いから考えると何かがおかしい挙動になっています。
どうしようか?
いくつかアプローチは考えられますが、ここでは順序を逆にしてみることにします。つまり、先に絞り込みをした後でページネーション用に制限してドキュメントを表示するという方法です。
順序逆アプローチを試す
前提として、ページ番号と検索語句の両方が指定された状態でAPIが発行されたものとします。
ドキュメントを絞り込む
let booksDocs = try! collection.find().filter({ book -> Bool in
return book.title.contains(title)
})先に全ドキュメントから絞り込みをします。絞り込みされたものはドキュメントの配列として得られます。
併せて、この時点でドキュメント数をカウントしておきます。ページネーション時の総ドキュメント数と総ページ数を把握するためです。
指定したページに表示するために必要なドキュメントを取り出す
すでにドキュメントが配列に入った状態ですので、シンプルに配列の操作です。
for (index, bookRaw) in booksDocs.enumerated() {
if index >= (pageNumber-1)*LIMIT && index < (pageNumber-1)*LIMIT + LIMIT {
let book = Book(id: bookRaw._id?.hex ?? "", title: bookRaw.title, publisher: bookRaw.publisher, price: bookRaw.price)
books.append(book)
}
}ページ番号とページに表示する最大ドキュメント数を用いて、必要なドキュメントだけを取り出します。
なお、BookはLeafテンプレートのレンダリングをするために使うデータモデルです。ObjectIdの関係で、MongoDBのためのデータモデルと区別しています。
// MongoDBデータモデル
struct BookDB: Content,Codable {
var _id: ObjectId?
var title: String
var publisher: String
var price: Int
}
// Leafテンプレート用データモデル
struct Book: Content,Codable {
var id: String
var title: String
var publisher: String
var price: Int
}Leafテンプレートをレンダリングする
残るは、取り出されたドキュメントの配列とページ番号、ドキュメントの総数、検索語句をLeafテンプレートに渡すだけです。
この辺りはページネーションの時とほぼ同じですので割愛します。変わったところといえば、次のページと前のページのリンク先のパスに検索語句をクエリパラメータで付けておくところぐらいでしょうか。

まとめ
![]()
1ページ目 ![]()
2ページ目

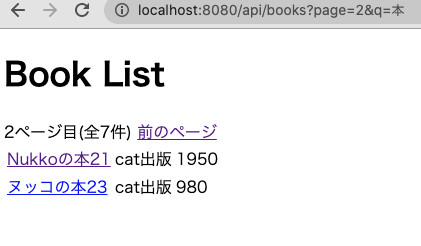
部分一致絞り込みとページネーションができています。
URLにクエリパラメータを直打ちしましたが、検索語句を入れるテキストボックスをつけるといい感じになりますね。

